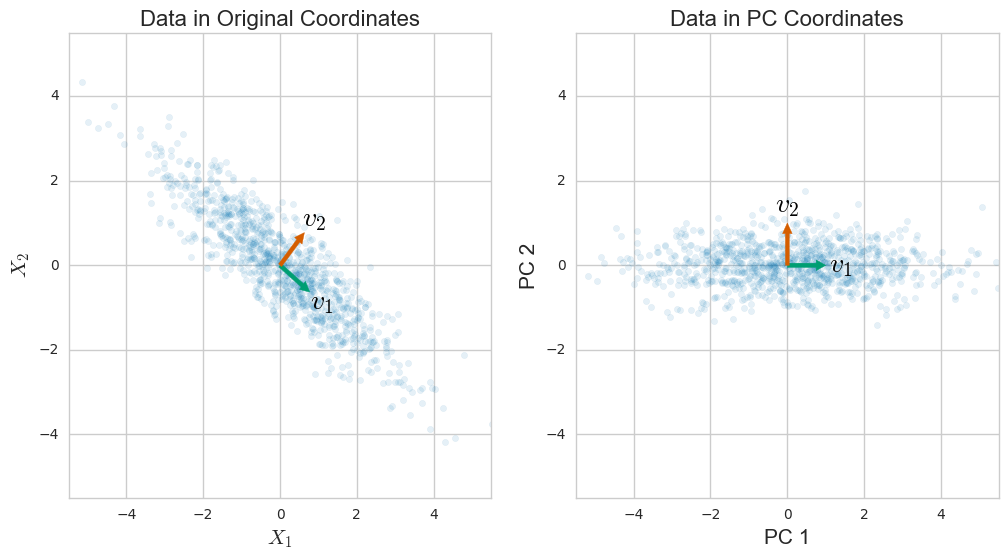
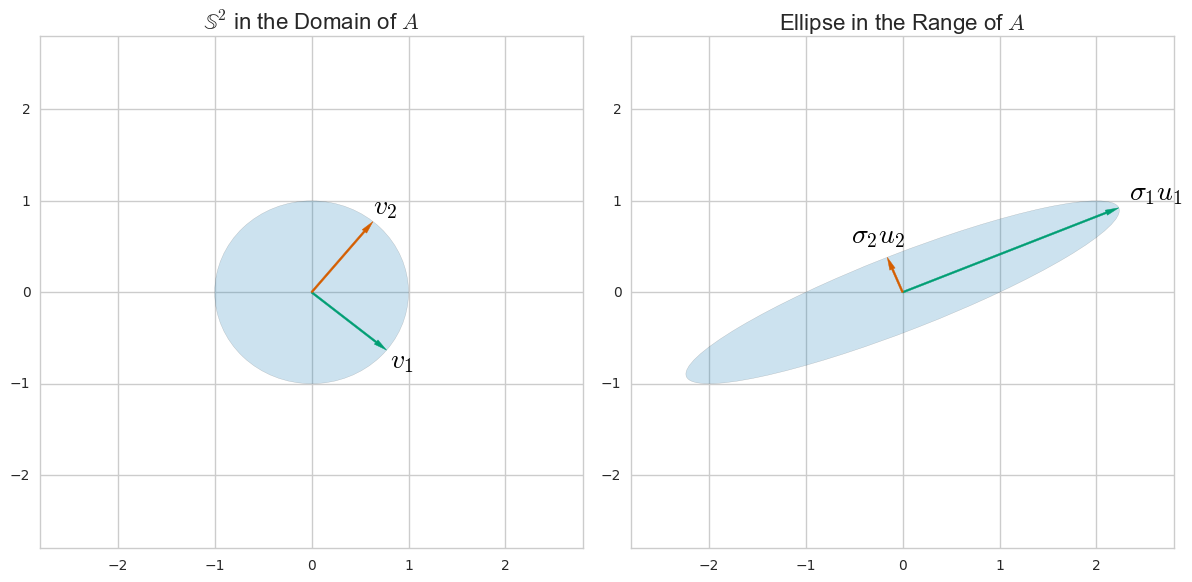
El análisis de componentes principales (PCA) generalmente se explica a través de una descomposición propia de la matriz de covarianza. Sin embargo, también se puede realizar a través de descomposición en valores singulares (SVD) de la matriz de datos . ¿Como funciona? ¿Cuál es la conexión entre estos dos enfoques? ¿Cuál es la relación entre SVD y PCA?
O, en otras palabras, ¿cómo usar SVD de la matriz de datos para realizar la reducción de dimensionalidad?
8
Escribí esta pregunta de estilo de preguntas frecuentes junto con mi propia respuesta, porque con frecuencia se hace de varias formas, pero no hay un hilo canónico y, por lo tanto, es difícil cerrar los duplicados. Proporcione meta comentarios en este meta thread adjunto .
—
ameba
Además de una excelente y detallada respuesta de la ameba con sus enlaces adicionales, podría recomendar comprobar esto , donde PCA se considera junto a otras técnicas basadas en SVD. La discusión allí presenta álgebra casi idéntica a la de la ameba con una pequeña diferencia de que el discurso allí, al describir PCA, trata sobre la descomposición svd de [o ] en lugar de , que es simplemente conveniente ya que se relaciona con el PCA realizado a través de la descomposición propia de la matriz de covarianza. X/ √ X
—
ttnphns
PCA es un caso especial de SVD. PCA necesita los datos normalizados, idealmente la misma unidad. La matriz es nxn en PCA.
—
Orvar Korvar
@OrvarKorvar: ¿De qué matriz nxn estás hablando?
—
Cbhihe