He tenido esta pregunta por meses. Parece que simplemente adivinamos el softmax como una función de salida y luego interpretamos la entrada al softmax como probabilidades de registro. Como dijiste, ¿por qué no simplemente normalizar todos los resultados dividiéndolos por su suma? Encontré la respuesta en el libro Deep Learning de Goodfellow, Bengio y Courville (2016) en la sección 6.2.2.
Digamos que nuestra última capa oculta nos da z como una activación. Entonces el softmax se define como

Muy corta explicación
La exp en la función softmax cancela aproximadamente el registro en la pérdida de entropía cruzada, causando que la pérdida sea aproximadamente lineal en z_i. Esto conduce a un gradiente aproximadamente constante, cuando el modelo está equivocado, lo que le permite corregirse rápidamente. Por lo tanto, un softmax saturado incorrecto no causa un gradiente de fuga.
Breve explicación
El método más popular para entrenar una red neuronal es la Estimación de máxima verosimilitud. Estimamos los parámetros theta de una manera que maximiza la probabilidad de los datos de entrenamiento (de tamaño m). Como la probabilidad de todo el conjunto de datos de entrenamiento es un producto de las probabilidades de cada muestra, es más fácil maximizar la probabilidad logarítmica del conjunto de datos y, por lo tanto, la suma de la probabilidad logarítmica de cada muestra indexada por k:
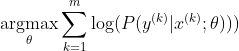
Ahora, solo nos centramos en el softmax aquí con z ya dado, por lo que podemos reemplazar
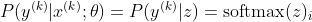
siendo yo la clase correcta de la késima muestra. Ahora, vemos que cuando tomamos el logaritmo del softmax, para calcular la probabilidad logarítmica de la muestra, obtenemos:
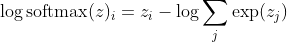
, que para grandes diferencias en z se aproxima aproximadamente a
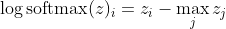
Primero, vemos el componente lineal z_i aquí. En segundo lugar, podemos examinar el comportamiento de max (z) para dos casos:
- Si el modelo es correcto, entonces max (z) será z_i. Por lo tanto, el logaritmo de probabilidad asintota a cero (es decir, una probabilidad de 1) con una diferencia creciente entre z_i y las otras entradas en z.
- Si el modelo es incorrecto, max (z) será otro z_j> z_i. Por lo tanto, la adición de z_i no cancela completamente -z_j y la probabilidad de registro es aproximadamente (z_i - z_j). Esto le dice claramente al modelo qué hacer para aumentar la probabilidad de registro: aumentar z_i y disminuir z_j.
Vemos que la probabilidad de registro general estará dominada por muestras, donde el modelo es incorrecto. Además, incluso si el modelo es realmente incorrecto, lo que conduce a un softmax saturado, la función de pérdida no se satura. Es aproximadamente lineal en z_j, lo que significa que tenemos un gradiente aproximadamente constante. Esto permite que el modelo se corrija rápidamente. Tenga en cuenta que este no es el caso del error cuadrático medio, por ejemplo.
Larga explicación
Si el softmax todavía le parece una elección arbitraria, puede echar un vistazo a la justificación para usar el sigmoide en la regresión logística:
¿Por qué la función sigmoidea en lugar de cualquier otra cosa?
El softmax es la generalización del sigmoide para problemas multiclase justificados de manera análoga.



