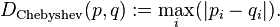TL; DR; Su problema no es realizar la función de distancia. Su problema es realizar la función de distancia tantas veces. En otras palabras, necesita una optimización algorítmica en lugar de una matemática.
[EDITAR] Estoy borrando la primera sección de mi respuesta, porque la gente la odia. El título de la pregunta pedía funciones de distancia alternativas antes de la edición.
Estás utilizando una función de distancia donde estás calculando la raíz cuadrada cada vez. Sin embargo, simplemente puede reemplazar eso sin usar la raíz cuadrada y calcular la distancia al cuadrado en su lugar. Esto te ahorrará muchos ciclos preciosos.
Distancia ^ 2 = x * x + y * y;
Esto es realmente un truco común. Pero debe ajustar sus cálculos en consecuencia. También se puede usar como verificación inicial antes de calcular la distancia real.
Entonces, por ejemplo, en lugar de calcular la distancia real entre dos puntos / esferas para una prueba de intersección, podemos calcular la Distancia al cuadrado y compararla con el radio al cuadrado en lugar del radio.
Edite, mucho después de que @ Byte56 señaló que no leí la pregunta y que estaba al tanto de la optimización de la distancia al cuadrado.
Bueno, en su caso, lamentablemente estamos en gráficos de computadora que tratan casi exclusivamente con el espacio euclidiano , y la distancia se define exactamente como Sqrt of Vector dot itselfen el espacio euclidiano.
La distancia al cuadrado es la mejor aproximación que obtendrá (en términos de rendimiento), no puedo ver nada superando 2 multiplicaciones, una suma y una tarea.
Entonces dices que no puedo optimizar la función de distancia, ¿qué debo hacer?
Su problema no es realizar la función de distancia. Su problema es realizar la función de distancia tantas veces. En otras palabras, necesita una optimización algorítmica en lugar de una matemática.
El punto es, en lugar de verificar la intersección del jugador con cada objeto en la escena, cada cuadro. Puede usar fácilmente la coherencia espacial para su ventaja, y solo verificar los objetos que están cerca del jugador (que tienen más probabilidades de golpear / intersectarse).
Esto se puede hacer fácilmente almacenando esa información espacial en una estructura de datos de partición espacial . Para un juego simple, sugeriría un Grid porque es básicamente fácil de implementar y se adapta muy bien a la escena dinámica.
Cada celda / cuadro contiene una lista de objetos que encierra el cuadro delimitador de la cuadrícula. Y es fácil rastrear la posición del jugador en esas celdas. Y para los cálculos de distancia, solo verifica la distancia del jugador con esos objetos dentro de las mismas celdas vecinas en lugar de todo en la escena.
Un enfoque más complicado es usar BSP o Octrees.