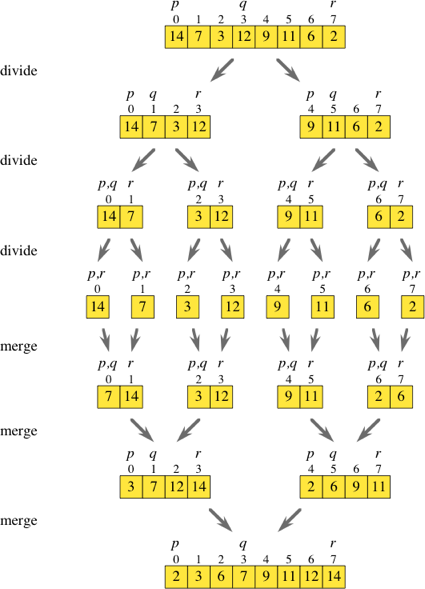
Por lo tanto, combinar sort es un algoritmo de divide y vencerás. Mientras miraba el diagrama anterior, pensaba si era posible omitir básicamente todos los pasos de división.
Si iteraba sobre la matriz original mientras saltaba por dos, podría obtener los elementos en el índice i e i + 1 y colocarlos en sus propias matrices ordenadas. Una vez que tenga todas estas sub-matrices ([7,14], [3,12], [9,11] y [2,6] como se muestra en el diagrama), simplemente puede continuar con la rutina normal de fusión para obtener Una matriz ordenada.
¿La iteración a través de la matriz y la generación inmediata de las sub-matrices requeridas es menos eficiente que realizar los pasos de división en su totalidad?
Relacionado: cs.stackexchange.com/questions/77075/…
—
Omar