Creo que es mejor si profundizo en su segundo punto con un movimiento de ejemplo en el juego 1 entre AlphaZero y Stockfish que también sirvió para satisfacer mi curiosidad hoy.
el límite de tiempo de 1 min / movimiento (¿Cómo perjudicaría a Stockfish?)
El rendimiento de Stockfish depende tanto del límite de tiempo como de la configuración del hardware, así que piense en cuando alguien duplica los hilos de la CPU, entonces Stockfish necesita menos tiempo (no necesariamente la mitad) para encontrar la solución de lo que lo haría con la primera configuración.
En el primer informe publicado en Chess.com, alguien afirmó que Stockfish no estaba jugando de manera óptima porque no podía reproducir los mismos resultados usando el mismo Stockfish en su computadora. Dijo que en la posición de abajo (juego 1 - movimiento 11) Stockfish jugó Kg1-h1 (movió a su rey), lo que no tenía ningún sentido. Por otro lado, stockfish en su computadora mostró un movimiento más desarrollado como Be3 (mover el alfil cuadrado oscuro), veamos la posición:
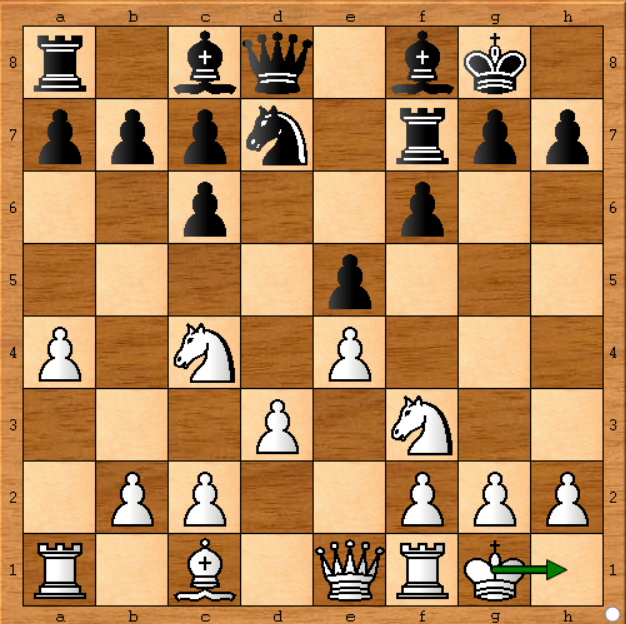
Sí, fue un movimiento pasivo y parece que Stockfish debería haber jugado un movimiento más desarrollado. Pero estaba equivocado. ¿Por qué? Debido a que corrió Stockfish durante 15 segundos, y si lo hubiera hecho durante una hora, habría obtenido Kg1-h1 como el mejor movimiento en esa posición. Stockfish cambia su decisión cuando analiza todos los movimientos posibles con más profundidad. Esto es lo que dije originalmente en mi respuesta :
Ejecuté el último stockfish en la posición (en el movimiento 11):
- Al principio, da b4 como el movimiento óptimo cuando el motor está funcionando durante aproximadamente un minuto. Después de eso, decide que Be3 es mejor.
Pero después de 5 minutos en mi hardware que se ejecuta en 1,400k nodos / s, decidirá usar Kh1 como el movimiento óptimo.
En el documento, se dice que stockfish calcula 70,000k posiciones por segundo y se ejecuta durante 1 minuto por movimiento, eso es aproximadamente 50 veces mi hardware, así que dejaré que el mío funcione durante 50 minutos ... Kg1-h1 sigue siendo el elección para Stockfish.
Límite de tiempo es la clave
En el caso anterior, probablemente no importaba mucho si Stockfish corría el doble de tiempo porque la decisión hubiera sido la misma, pero en el siguiente movimiento definitivamente :
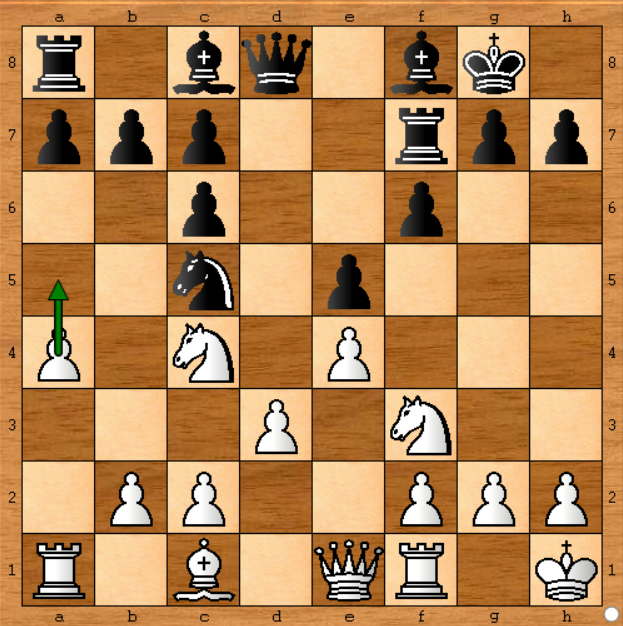
En esta posición, Stockfish eligió mover el peón del lado izquierdo ( a4-a5 ). Digamos que tengo una computadora que ejecuta el motor Stockfish a una velocidad de 1,400k nodos por segundo, que es aproximadamente 50 veces menor que el Stockfish en el juego real ( en el documento , dice 70,000kn / s). Entonces puedo simular el juego si lo ejecuto durante 50 minutos en cada movimiento. Bueno.
Ejecuté el análisis de Stockfish en la posición anterior y obtuve los siguientes resultados:
- Stockfish comenzó sugiriendo algunos movimientos, pero después de 6 minutos en mi computadora (corresponde a 7.2 segundos en el Stockfish en el juego real) prefirió a4-a5 tal como fue el juego .
Eso es bueno, pero lo mantuve funcionando durante 50 minutos completos para alcanzar los cálculos del Stockfish en el juego que se permitió 1 minuto:
La triste verdad es que creo que Stockfish perdió todos sus juegos debido al límite de tiempo. Stockfish obtiene una búsqueda y evaluación más profunda a medida que pasa el tiempo y en el juego no se le permitió usar un libro de apertura que lo hace considerar muchos movimientos en profundidades poco profundas. Tenga en cuenta que en el juego real se jugó a4-a5 que muestra que (suponiendo que pudiera evaluar 70 millones de posiciones por segundo) el Stockfish en el juego no pasó más de 21.6 segundos en movimiento. De lo contrario, habría cambiado su decisión a esos otros tres movimientos en el juego real. La razón de esto todavía no está clara para mí, ya que mi Stockfish también consumía menos memoria (aproximadamente ~ 130 MB de RAM en comparación con el 1 GB mencionado en el documento original , suponiendo que todo vaya a tablas hash).
Conclusión
El hardware que ejecutaba Stockfish, como señalé, fue en el mejor de los casos 18 veces más rápido que el mío (Actualización: en un solo núcleo) según el movimiento que analicé. No estoy seguro de si AlphaZero realmente podría hacer uso de dicho hardware para entrenar sus redes en 4 horas, solo puedo suponer que es demasiado bajo para un juego como el ajedrez. Además, AlphaZero pasó esas horas aprendiendo, lo que también incluye construir aperturas sólidas (y como señala el documento, preferencias sobre ciertas vacantes). Por otro lado, Stockfish fue discapacitado en las aberturas, y no evaluó 70 millones de posiciones por segundo durante 60 segundos en cada movimiento.
Como nota final, todas las cosas que dije se basaron en mis suposiciones. Por supuesto, el resultado de AlphaZero y los juegos fueron muy interesantes para mí. Sin embargo, me hubiera encantado ver un juego en el que el juego Stockfish fuera igual que el que tengo en mi computadora. Es decir, más tiempo y un libro de apertura permitido. También es fácil obtener los resultados del análisis de Stockfish en cada movimiento, y deseo que lo publiquen para mostrar qué tan bien funcionó.